记录一次线上celery task的耗时分析
这是一次线上报出来的诡异事件(至少起初是这么认为的)。对于同一个celery task, 开发环境上毫秒级的操作转移到AWS上后需要花费6秒左右。因此,呈现在UI上的表现会让用户极度抓狂。于是乎,性能优化被提到最高优先级。
第一阶段
首先梳理下整个请求过程,即从发起请求到获得响应的各个阶段。整个过程包括大致包含三个阶段(如Figure 1所示):1,django server获得请求,2,celery task的运行,3,django server返回响应。
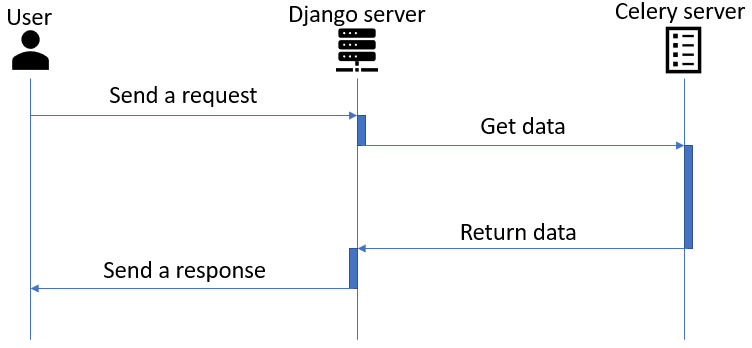
从流程上看,时间的开销主要花在celery server这端。那么分析目的就比较明确了,从celery server这端查看,寻找耗时处理的位置。 最开始的想法认为在数据处理这块可能因为AWS环境的不同导致某些算法的处理时间拉长。于是乎,我查看了处理逻辑的各个阶段的时间,结果是和本地并无太大差异。既然不是业务逻辑的处理问题,那么就把苗头指向了celery task。Celery task的运行包含几个阶段:1,task received;2,task running;3,task succeeded。因为celery task运行成功后的log显示整个任务的运行时间很长,即便运行一个空task也要花费6s左右的时间,所以猜测是不是celery在task pre/post-run的时候做了一些比较耗时的操作。
第二阶段
对celery task进行debug。去celery的官网上找了下,celery确实有一个debug工具rdb。利用rdb在代码中设置断点,然后使用telnet连接到celery的debug模式进行远程调试。具体参考celery document。在debug的过程中我们找到celery运行task的代码文件trace.py(参考celery github)。单纯的debug只能了解task的运行过程,但并不清楚各个阶段的耗时情况(应该类似profiling的功能,时间紧急我也没去找)。于是,我就手动修改trace.py源码,加入不同阶段时间打印。结果发现耗时地方在task运行阶段(即Figure 2标记的位置)。
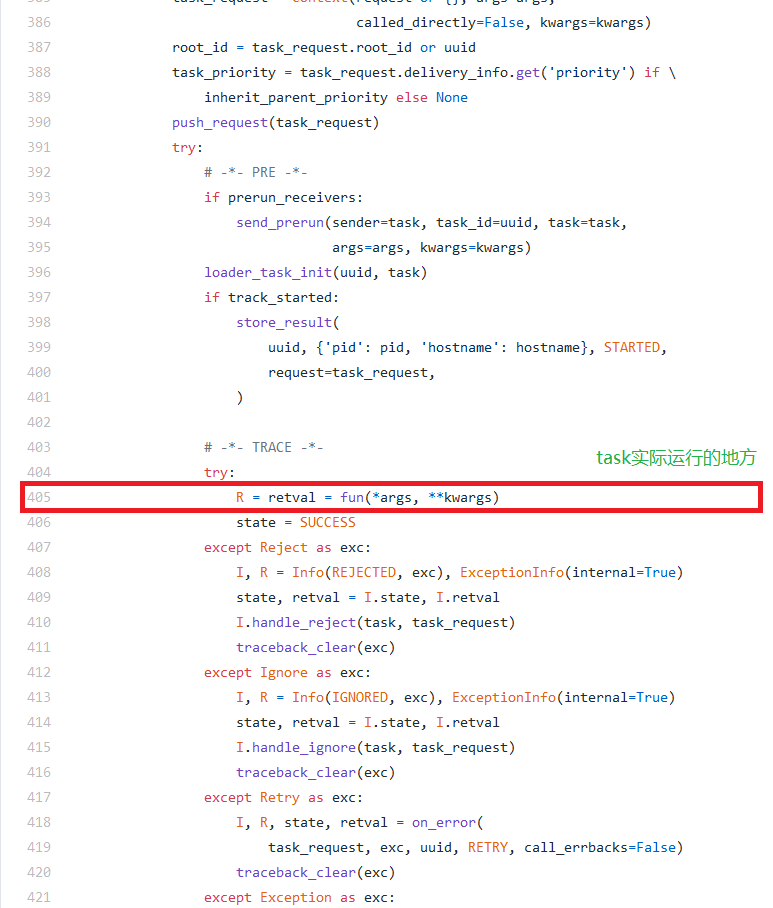
第三阶段
此时已经筋疲力尽,心想难不成task运行过程中celery也做了啥操作?由于这个fun()函数是一个被传入进来的参数(内心已经那啥了…),于是乎再次进入debug模式仔细的查看下fun()中究竟做了什么。结果显示这锅还真不是人家celery该背的,追踪发现celery在task运行的时候还真没干啥特殊操作。看来还是自己代码的问题。
最终阶段
既然不是业务处理的问题,那难不成是在对象实例化的时候构造函数里有什么问题?顺着这个思路,我查了下构造函数的运行时间。你猜怎么着?问题找到了(内心苦笑,闹了个大乌龙)!原因是在创建对象的时候涉及到数据库和s3的连接操作(耗时情况如table 1所示)。虽然过程曲折,但一番经历后也确实学到了一些东西,感觉对某些知识的理解又提升了一点点,不枉我花了这么长的时间。
Table 1, 连接耗时统计
| 运行阶段 | 耗时情况 |
|---|---|
| db connection | 单次连接0.1s左右(共发生了两次) |
| s3 connection | 单次连接1s左右(共发生了五次) |
于是我重构了这块代码,对连接进行了统一管理。不过需要注意的是,在AWS上一定要做好重连机制,因为token在一定时间后可能会失效。
总结
1,一定不要乐观地认为线上运行跟本地一样(或者自认为不会有什么大差异)。
2,问题有时候会出现在容易被遗漏的地方,一定要注重细节。
3,在类的实现中最好不要在构造函数里面加入耗时操作。
4,对于资源管理相关(如数据库连接)的处理,最好进行统一管理(如数据库连接池)。