numpy.dot的内存使用问题
问题描述
这又是一个线上问题(不得不说要做出一个稳定能用的产品已然不易)。起初的现象是线上偶尔会报警(显然有bug出现了嘛): Worker exited prematurely: signal 9 (SIGKILL)。这是个什么玩意儿?之前没见过啊!在google上一顿操作,大概有了些眉目。 大部分解释都指向了linux OOM(Out Of Memory)机制。 那…我遇到的会是这个问题吗?带着问题先去AWS测试机上复盘(这是个偶发性问题,复现得看人品😔),从观察到的结果来看,确实如此(如Figure 1和Figure 2所示)。 想了解更多OOM知识,推荐大家参考《理解Linux的memory overcommit》, 不过更推荐大家直接阅读linux kernel document。


问题追踪
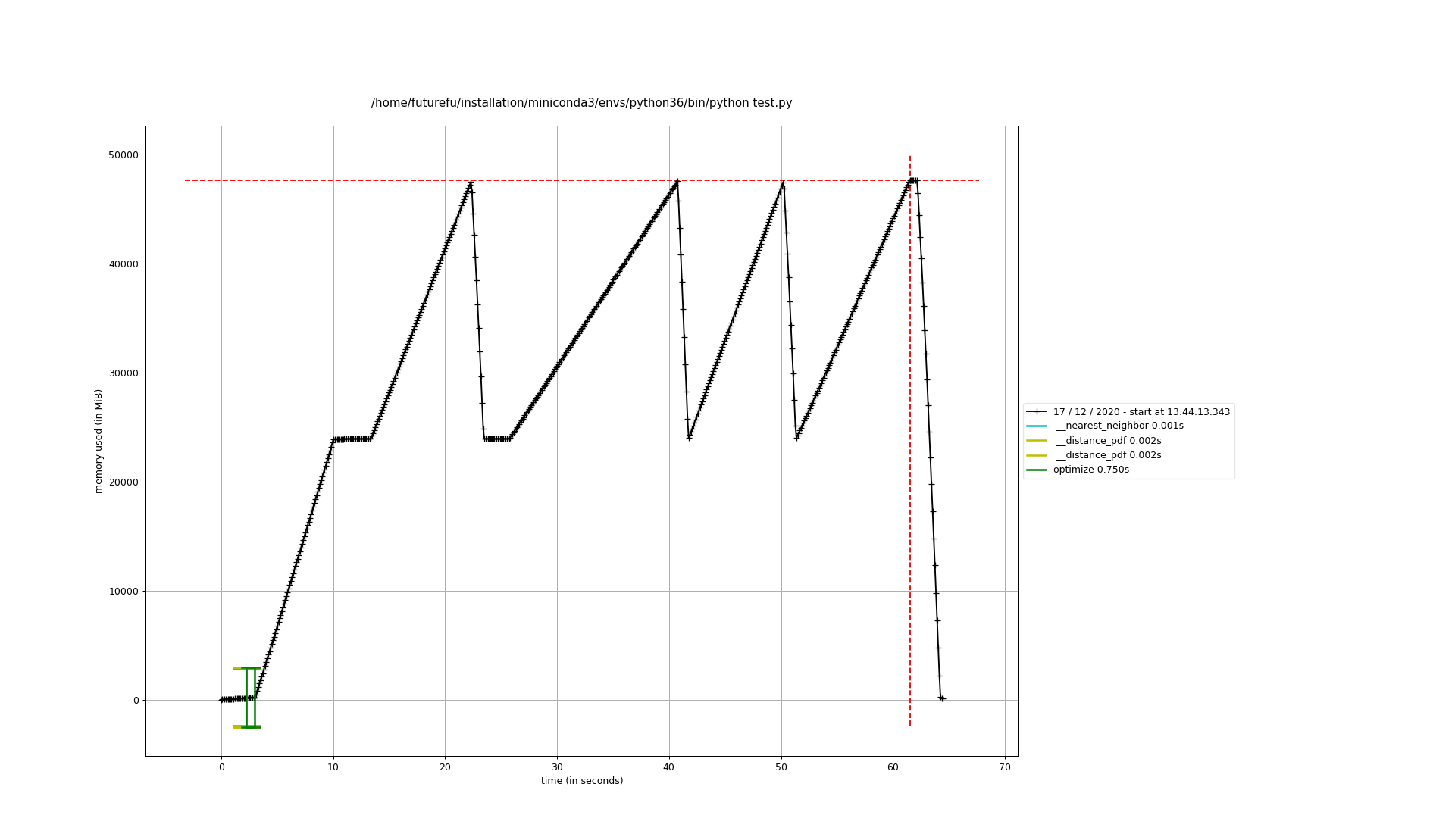
一开始觉得是celery的问题,是不是task管理不善出现了内存泄漏?去celery的github主页上调查了一番,虽然celery确实出现过此类问题,但貌似跟我遇到的情况不太一样。另外,从复盘的情况上看,我发现问题出现时都是停在了压缩算法这块儿。这意味着极有可能是我们的算法出了问题,毕竟算法涉及了大量的矩阵运算和积分运算。顺着这个思路,我尝试直接运行算法来看看是不是可以重现问题。没错,问题确实重现出来了。Figure 3是使用memory_profiler分析出来的内存使用趋势图。显然,内存申请已接近50GB了。那究竟是哪块儿代码会需要如此大的内存呢?继续使用memory_profiler分析,如图Figure 4所示,到此,问题已经比较明确了。
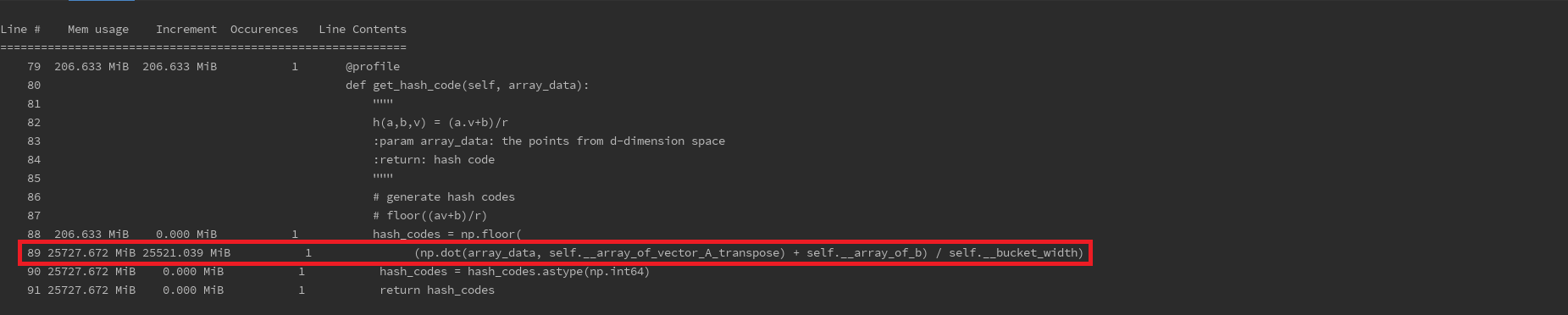
为了做最终确认,我到numpy的github主页上搜索了相关issue,确实存在类似问题(参考numpy issues)。但,仔细想想,numpy的这个bug是在两个空矩阵做内积时就会出现,而我们的算法不会出现空矩阵相乘且问题只是偶尔发生。所以,可能我们遇到的问题不太一样。那就查看下究竟是多大的矩阵相乘导致问题的发生。取其中一个结果进行验证,矩阵大小分别是499993x4和4x6409,观察numpy.dot()运算过程,确实申请了非常大的内存,如图Figure 5所示。仔细想来:numpy的做法属于正常操作,两个矩阵内积结果的大小为499993x6409,全double类型的数据确实需要很大的存储空间。既然不是numpy的问题,那就得想法来减少内存开销了。

解决方案
目前来看,短时间内还找不到替代算法。那我能想到的一种方式就是对矩阵进行切分了,对切片矩阵单独计算,然后拼接结果(如Formular 1所示)。
……. (Formular 1)
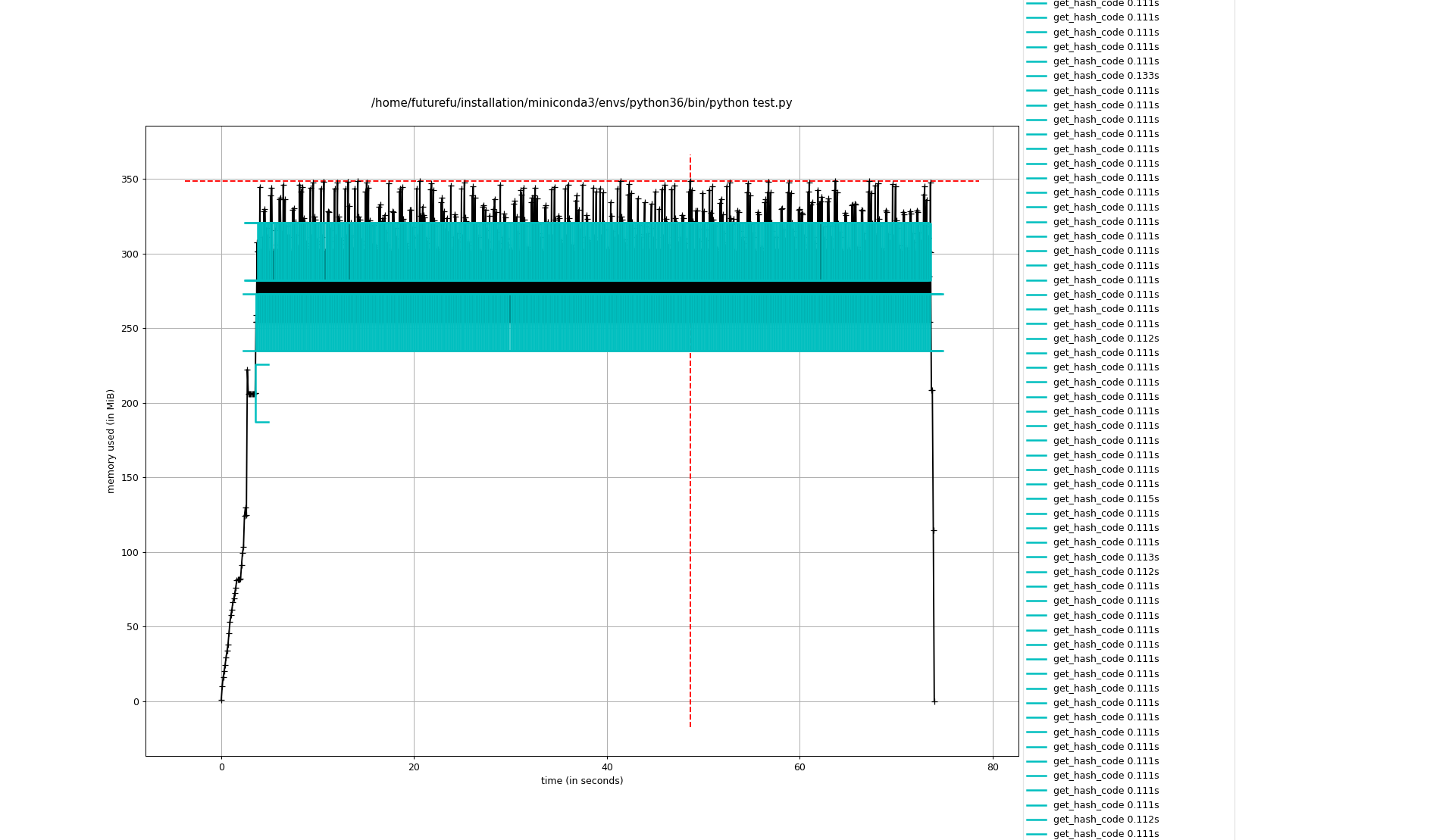
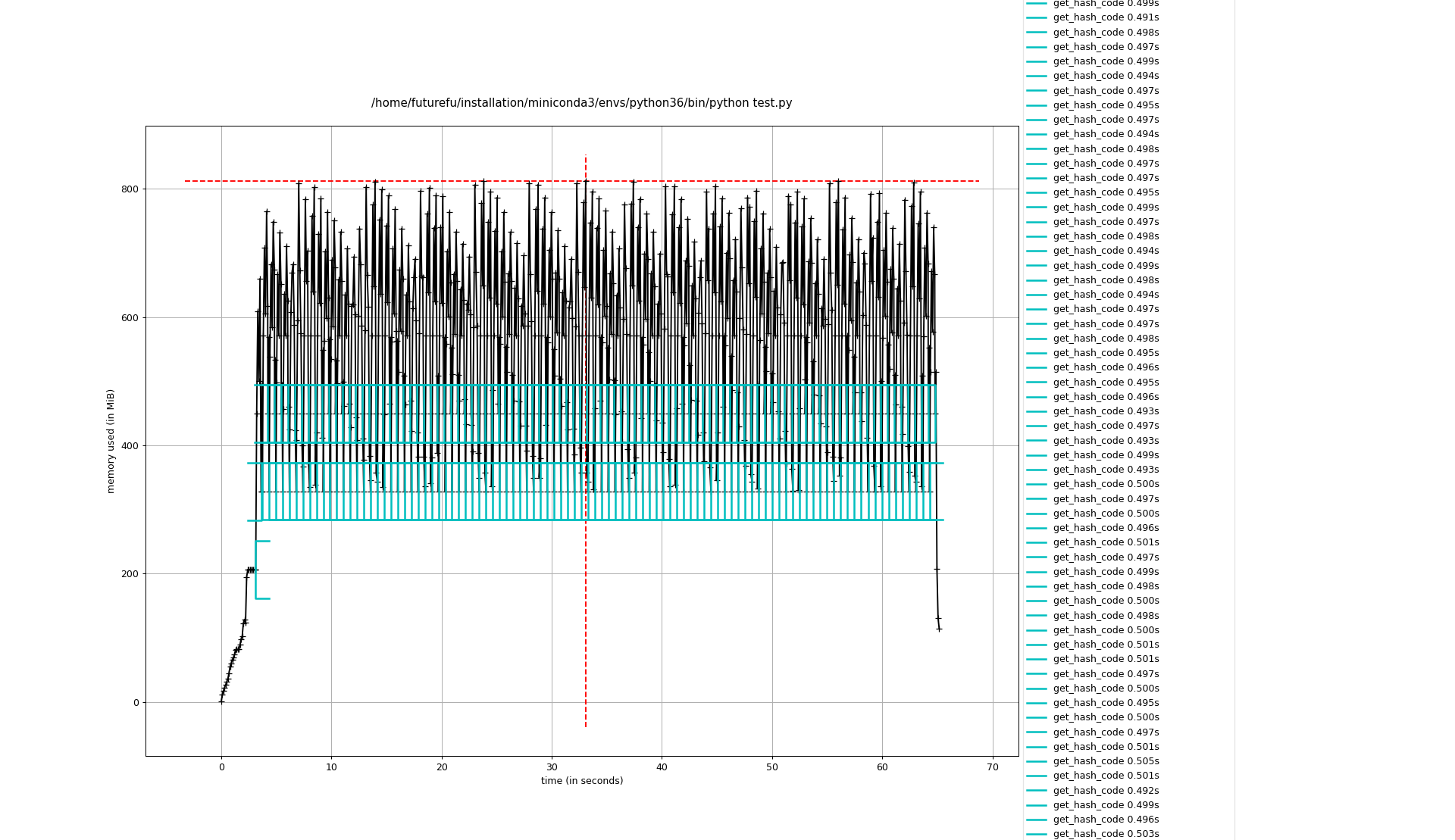
Table 2显示了不同切片大小的时间和内存消耗情况。鉴于当前的应用场景,我暂将切片大小定为5000。相比之前,时间也缩短了大概22.4%。
Table 2, 结果性能比较
| 切片大小 | 时间消耗(s) | 最大内存消耗(MB) | 详细 |
|---|---|---|---|
| 1000 | 71.17 | ~348 | 如Figure 6所示 |
| 5000 | 62.84 | ~800 | 如Figure 7所示 |
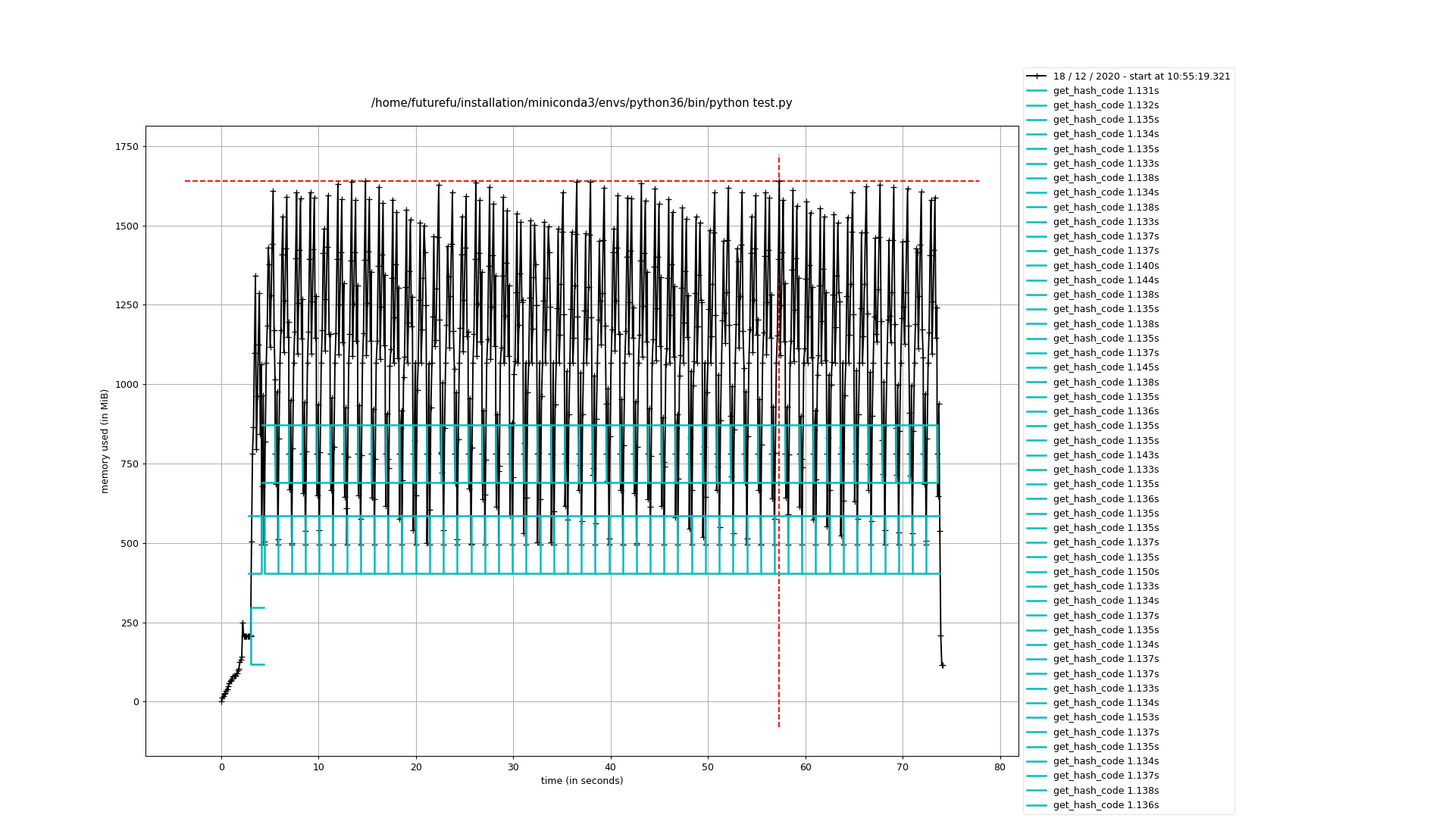
| 10000 | 71.9 | ~1625 | 如Figure 8所示 |
未来展望
当然,我也尝试过使用多线程来加快运算时间(提升了70%左右),但考虑到内存的消耗远远超过1GB(最大到达10GB左右),所以目前暂不考虑此种方式。不过未来倒是可以考虑下多台机器分布式计算的方式,或许在时间上可以有很大的提升。但,我觉得如果能针对算法本身做一些优化或许更好。
总结
这次经历也算是收获不少。虽是软件开发,但一定要考虑硬件资源的管理。尤其像内存这样的宝贵资源,要尽可能的合理利用,不然极有可能导致应用崩溃。
参考资料
[1] https://stackoverflow.com/questions/22805079/celery-workerlosterror-worker-exited-prematurely-signal-9-sigkill
[2] http://linuxperf.com/?p=102
[3] https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
[4] https://github.com/numpy/numpy/issues?q=memory+leak+dot